Three Charts to Watch at NVIDIA's GTC: Cheaper Compute, Spend More



Last night, Huang Renxun announced the Vera Rubin platform at GTC 2026, claiming that the power consumption per inference performance is 10 times higher than Blackwell, the cost per inference Token has been reduced to one-tenth, and hinted that the merger order between Blackwell and Vera Rubin will exceed $1 trillion by 2027.
Over the past two years, the inference cost of GPT-4-level APIs has plummeted by 94%, from $36 per million Tokens to less than $2. Intuitively, with the decrease in computing costs, businesses should be spending less. However, the combined capital expenditures of the four cloud providers Amazon, Alphabet, Meta, and Microsoft have increased from $154 billion to $416 billion, nearly tripling.
Huang Renxun's trillion-dollar hint is not just a marketing slogan; it is backed by a curve that can be drawn with data.
Each Generation Makes the Previous Generation Seem Pathetic
From the H100 of 2022 to the Vera Rubin set to be mass-produced in the second half of 2026, NVIDIA's AI GPU FP8 dense inference computing power has increased 8-fold in four years. According to NVIDIA's official specifications, the H100 single card has 2.0 PetaFLOPS, the B200 reaches 4.0 PF, and the Vera Rubin directly jumps to 16 PF.
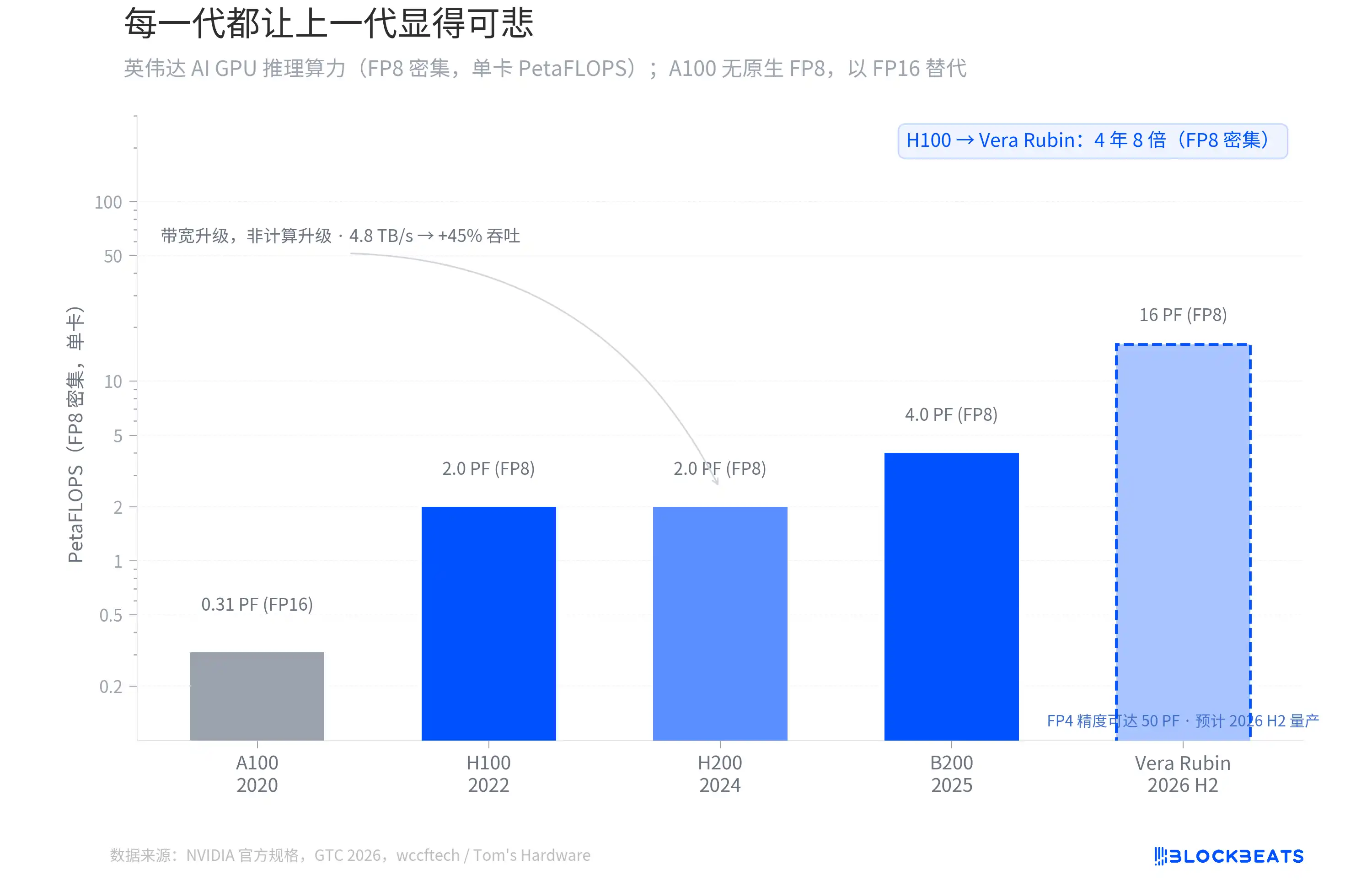
However, not every generational leap comes from the same place. According to wccftech, the H200's computing cores are identical to the H100, with no change in FP8 computing power; all its upgrades come from memory bandwidth (increased from 3.35 TB/s to 4.8 TB/s), bringing about a roughly 45% inference throughput increase.
The real architectural transition occurred between B200 and Vera Rubin. Vera Rubin adopts TSMC's 3nm process, featuring a dual-chiplet design with 336B transistors, achieving 50 PF of computing power at FP4 precision. According to Tom's Hardware, the first Vera Rubin system is already running on Microsoft Azure.
There is a subtle distinction that is easy to overlook. When Huang Renxun mentioned "10 times" at GTC, he was referring to the reduction in Token cost per inference, not a multiple of the original computing power. The Token cost includes Transformer Engine optimization, FP4 precision, larger batch inference, and other system-level factors. Looking at standardized FP8 dense TFLOPS, Vera Rubin is 4 times greater than Blackwell and 8 times greater than H100.
The slope of this curve has never slowed down. Each generation of GPUs has made the previous generation look inadequate, and that is exactly the starting point of the story to be told next.
Jevons Paradox: The cheaper the computational power, the more is spent
In March 2023, when GPT-4 was just launched, the API call cost was about $36 per million Tokens. According to OpenAI's official pricing history, by the mid of 2024 with the introduction of GPT-4o, it dropped to around $7, and by the end of 2025, the actual available price had fallen below $2. A decrease of over 94% in two years.
Logically, with inference costs dropping so much, businesses should spend less. However, the reality is quite the opposite. According to various company's financial reports and data tracked by Platformonomics, the combined annual capital expenditure of the four cloud providers Amazon, Alphabet, Meta, Microsoft increased from $154 billion in 2023 to $416 billion in 2025, a growth of 170%. Google alone surged from $32 billion to $91.5 billion (about 2.9 times), with Microsoft's increase even greater.
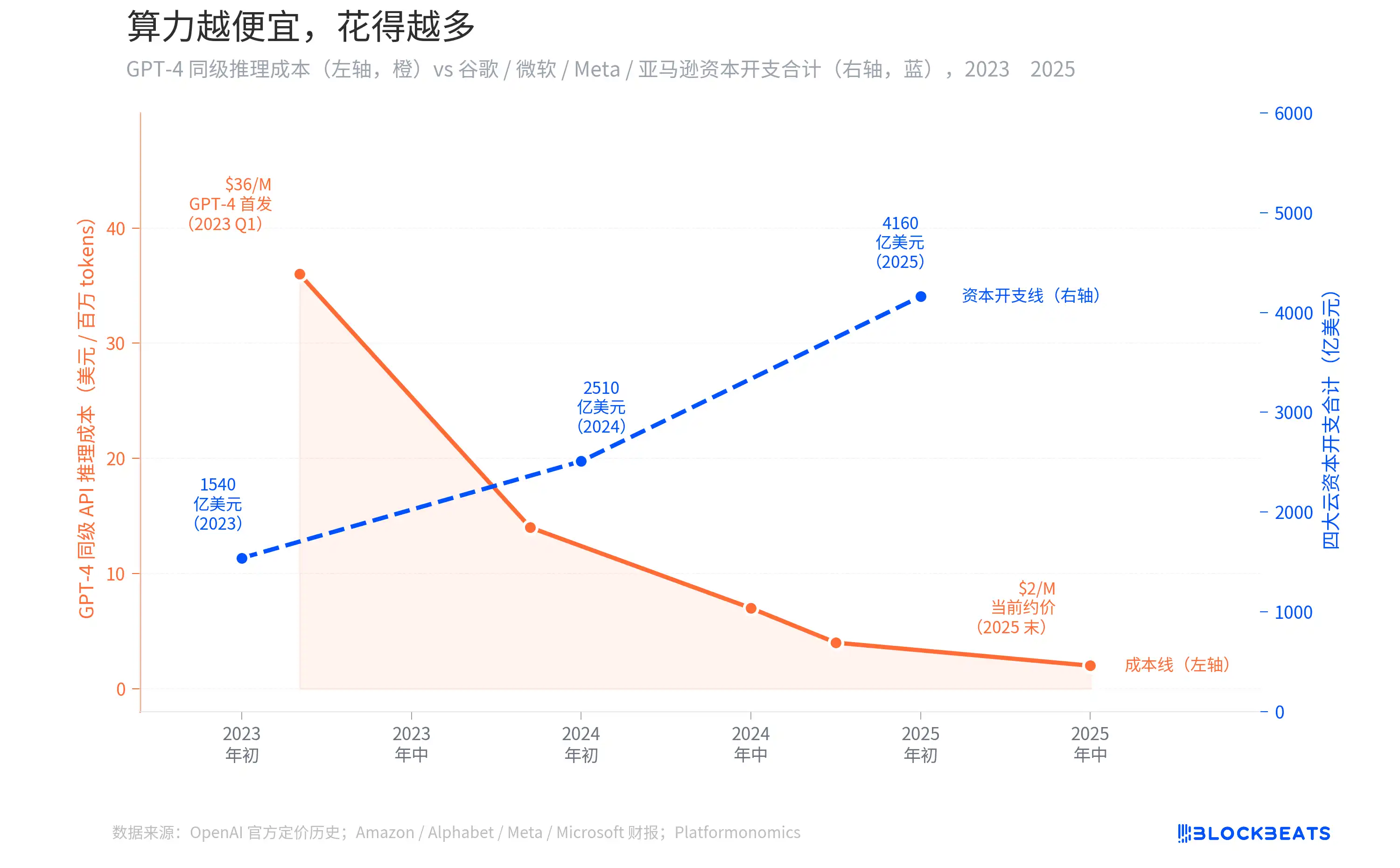
This phenomenon has a name in economics, called the Jevons Paradox. In 1865, the British economist William Jevons found that Watt's improvements to the steam engine significantly increased the efficiency of coal use, but the coal consumption in the UK did not decrease; instead, it rose. The reason is simple: the efficiency improvement made the steam engine more cost-effective, so more industries started using steam engines, and total demand expanded far beyond the part saved by efficiency.
Today, the situation with AI inference is exactly the same. As API prices plummeted to 6% of their original, enterprises did not save budget because of it but started fitting AI into previously uneconomical scenarios. Every new scenario like customer service, code review, content generation, search reordering, ad bidding is consuming more inference power. The expansion of demand far exceeds the rate of cost decline. In early 2025, DeepSeek R1 pushed the input price to $0.55 per million Tokens, further accelerating this cycle. The two lines moving in opposite directions on the chart represent two sides of the same coin.
Three years, an 11-fold increase, and no sight of a ceiling
If the Jevons Paradox has a most direct beneficiary, it is the one selling shovels.
According to NVIDIA's financial report, the data center business's annual revenue increased from $10.6 billion in FY2022 (ending January 2022) to $115.2 billion in FY2025 (ending January 2025), a growth of 10.9x over three fiscal years. This growth curve has almost no precedent in tech history. For comparison, after the iPhone was launched in 2007, it took Apple about 6 years to achieve a similar order of magnitude revenue scale increase.
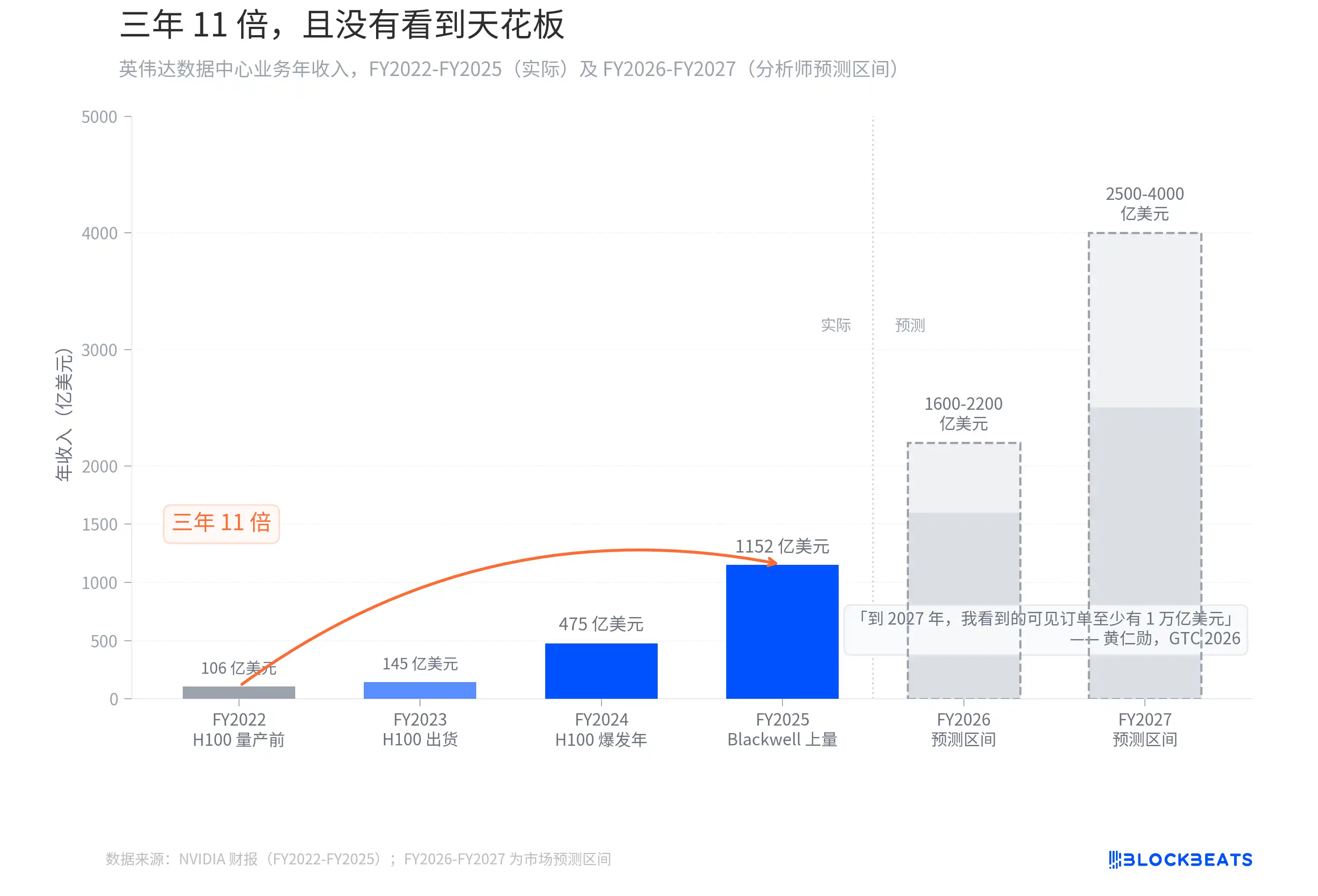
Then, Jensen Huang said at GTC 2026, "By 2027, the visible orders that I see are at least $1 trillion. In fact, our capacity will not be enough. I am confident that the computing demand will far exceed this number."
His forecast last year at GTC was around $500 billion in visible orders by 2026. A year later, the number doubled, with the time window extended by just one year. Analysts' revenue forecasts for FY2026-FY2027 range between $160-220 billion and $250-400 billion, respectively. However, Huang himself stated that this number is not a ceiling, "the computing demand will far exceed this number." On the day GTC ended, NVIDIA's stock price rose by 4.3%. The market evidently chose to believe him.
Each generation of GPU makes the previous look pitiful, and each round of price cuts makes the next round of capital expenditure seem natural. NVIDIA is currently situated in the sweetest spot of this paradox.
You may also like

Why Tokenized Stocks Are Booming in 2026 While Crypto Is Still Struggling
From Pump.fun to Collector Crypt: Has Solana's income throne changed hands?
Looking at Stripe's ambitions and the future of stablecoins from OUSD
Do you want to buy CRCL?
Wosh: Inflation has cooled in recent weeks, AI is reshaping the economy, and forward guidance has lost its necessity
The most secretive AI winner
Former ByteDance employee's account: How I started with two Pinduoduo hard drives and made six times the profit with Seagate to achieve financial freedom?
MiCA reshuffle begins, Binance temporarily bids farewell to the EU
How does Gate redo "buying and selling stocks" from the cryptocurrency world to the stock market?
Visa and Mastercard join 140 giants to launch a new stablecoin, but the impact on the market landscape may still be limited
Circle CEO responds to OUSD's challenge: Stablecoins are a winner-takes-all business, and we will not slow down
Argentina vs Cape Verde: When a Record-Breaking Legend Meets an Unbreakable Underdog
WEEX exclusive pre-match analysis of Argentina vs Cape Verde, exploring Messi-led Argentina’s dominance and Cape Verde’s historic defensive breakout, with a breakdown of volatility, structure, and match dynamics.
WEEX Launches Depth Chart for Spot Trading
Raising interest rates to protect STRC and selling coins to maintain credit, this time the strategy has chosen the two most expensive paths
Morning Report | Samsung announces a 265.5 trillion won investment plan, focusing on semiconductor and AI computing power data centers; Vitalik publishes an article detailing the entire technology tree behind the confusion protocol (iO) mainline
In the era of AI, what is left of Bitcoin?
NeoSoul announced plans to integrate with the OKX Agentic Wallet, promoting AI agents' participation in the on-chain economy
